Google Cloud Spannerを使った際に感じた良かった点と注意点
みなさま、こんにちは!
システム開発部のK.Mです。
弊社でGoogle Cloud Spannerをデータベースに使用する機会がありましたので、開発・運用時に感じた良かった点・注意点を個人的な見解を交えて記載していきます。

Google Cloud Spannerとは
Googleが開発した分散データベース
RDBMSとNoSQLの良い部分が合体したデータベース
良かった点
フルマネージドなので運営中に手がかからない
- 運営期間中は追加実装など他業務に集中出来る。
実際の運用時にspannerが落ちて繋がらなくなるということはありませんでした - イベントなどの負荷が上がりそうな時に事前にノード数を増やしたり、アクセス数が落ち着いてからノード数を減らすという作業しか行っていない
- それ以外だと1日1回GCPの管理画面からspannerのCPU負荷やレイテンシに問題が発生していないかを確認する程度の作業量でした
- 運営期間中は追加実装など他業務に集中出来る。
データの水平・垂直分割しなくてもspanner側で勝手にやってくれる
運用時にメンテナンスを入れずにスキーマー変更が可能
- 使用した案件では、本番環境にて動作確認をするためのメンテナンスを入れるという工程があったため、メンテナンス中にスキーマー更新を行っていたが、運営サイクルにてメンテナンスを無くすことを検討しているのであれば、魅力的な機能
配列型や構造体型でデータが持てる
- DBの設計がすっきりして、プログラム側での処理がしやすくなる
- 配列型の一例
ストーリーの第何話を読んだというのを単純に実装しようとして、ユーザーIDと読んだストーリーの話数を保存するテーブルを作った場合、下記のように読んだストーリー数分のレコードが作られてしまいデータが膨れ上がるし、selectやinsert、updateの速度にも影響が出てしまう。(インデックスを設定すればselect自体の速度は速くなるが、insertの速度がデータが増えていくたびにインデックスの更新も入り遅くなっていきますので通常は取りえない設計)
ユーザーID 読んだストーリーID 1 1 1 2 1 3 2 1 2 2 次に考えられるのが無駄にレコードが作られないように、読んだストーリー部分をカンマ区切りの文字列などで保存するという方法がある。こうすることで、ユーザー数分のレコードで済むのでデータ数は激減するが、プログラム側でDBからの読み込んだ際に、カンマで区切られた文字列をカンマ毎に分けて数字にしたり、DBに書き込む際に、数字をカンマで連結して文字列にしたりという処理が入ってきて、少し煩雑になってしまいます。
ユーザーID 読んだストーリーID 1 "1,2,3" 2 "1,2" そういった諸々を回避する方法として読んだストーリーIDをint型の配列型に設定することが可能になっています。配列型に設定出来る型自体は自由です。
ユーザーID 読んだストーリーID 1 [1,2,3] 2 [1,2] goの場合ですが、spannerから読み込んだ時点でint型のスライス(goでの配列のようなもの)として扱えるようになっているので、追加する場合は下記のように
appendするだけでデータが追加されます。
ストーリーテーブル.読んだストーリーID = append(ストーリーテーブル.読んだストーリーID, 4)
spannerの管理画面にて下記のような統計を表示するページがあり、クエリのCPU使用率や実行回数、レイテンシが見れるので調査のためにSQL(EXPLAINとか)を叩かなくてもブラウザ上で確認が出来るので調整が簡単に行える

GCP標準機能であるトレースにて、スタックトレースのようにspannerのコール順が分かるので、チューニング時にネックになっている箇所が分かりやすい。
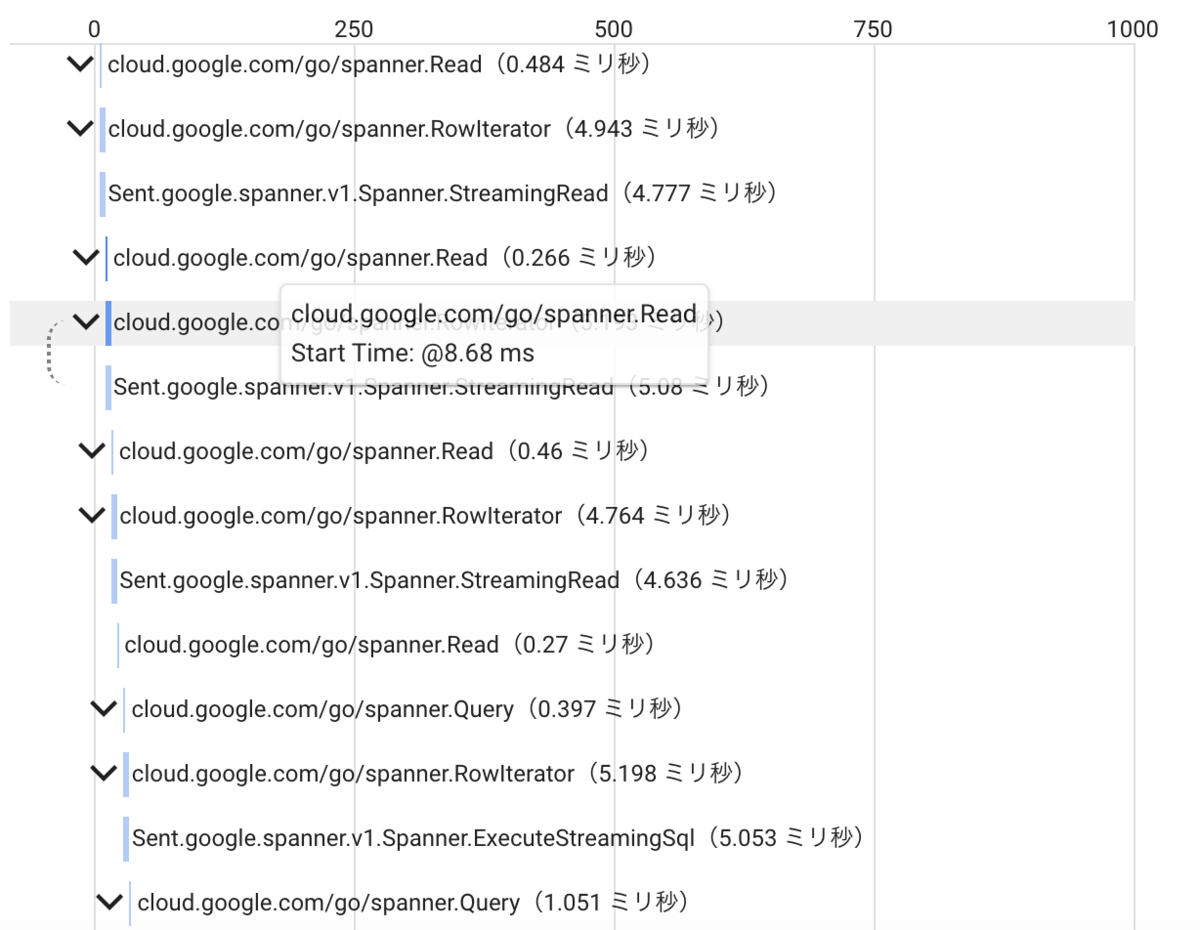
注意点
リリース前に暖機運転しておく必要がある。
インデックスの設定の仕方にクセがある。
トランザクションにクセがある。
- ここもノウハウ化されているが、何も知らないとハマる部分
- 自分が開発中によく起こったのが、timestamp型にallow_commit_timestampというオプションを設定出来るのですが、この値をtrueにしているとコミット順をアトミックに格納するようになります。その際に、ローカルの開発環境とspannerがあるサーバーとの時間が少しずれていることで、commit時に未来時間で書き込もうとしたというエラーで弾かれるという現象がありました。
error: spanner: code = "FailedPrecondition", desc = "Cannot write timestamps in the future 2018-10-02T06:07:31Z > 2018-10-02T06:07:30.765848Z (current time) because the allow_commit_timestamp column option is set to true for column テーブル名.ts, or for a corresponding shared key column in this table's interleaved table hierarchy." - このエラーが発生した場合は、ローカルの開発環境の時計を再設定することで発生しなくなることを確認しています。
公式にallow_commit_timestampの説明があります。
インターリーブというテーブルの親子関係を設定する特殊な項目がある。
- ここもノウハウ化されているが、何も知らないとハマる部分
- 弊社では、ユーザーのデータに関連するテーブルはメインとなるユーザー用のテーブルから全てインターリーブする形にしました
このような感じで、MySQLやPostgreSQLとかを使ってた人からすると色々なお作法がそれなりに存在しています。
【開発当時のお話】ローカル環境で動くspannerが無かった
【開発当時のお話】バックアップ・バックアップ戻しが簡単に出来なかった。
- エクスポート処理をCIで動かして日次でバックアップを取得する形にしたが、いつの間にかバックアップ機能が標準で追加されていた
後からカラム追加する時にNotNull指定が出来ない。
- イベントなどで後から既存のテーブルへカラムを追加する際に、NotNullにしておきたい場合があるのだが、spannerの仕様的な問題なのか、カラムを後から追加する時にはNotNull指定が出来ない。
- 既にデータが存在するテーブルにカラム追加すると全部初期値でNullになる仕様のせいなのか?
- 回避する方法としては、追加したカラムの値をNullから空白とかに変更してからALTER文でNotNull変更という一手間かける形で対応は可能
- イベントなどで後から既存のテーブルへカラムを追加する際に、NotNullにしておきたい場合があるのだが、spannerの仕様的な問題なのか、カラムを後から追加する時にはNotNull指定が出来ない。
経営者視点から見るとランニングコストが高くみられがち。
- フルマネージドなサービスなので、ほぼ人の手はかからない点と水平・垂直分割の処理が不要という点でその部分にかかる工数(人件費)を考慮してもらうように働きかける必要あり
開発時、運用時に起きた他の事例
- コミットする時の上限件数が決まっていたのを知らずに、エラーが発生した件
- 1回にコミットする上限件数が20000ミューテーションというのが決まっているのだが、それを知らずにエラーを出して困ったお話です。
- 開発中とあるバッチ処理を作成時に、テーブルにデータを追加・変更する時に対象ユーザー数が多いと何故かエラーになることがあったので調べてみると、1コミット20000ミューテーションという決まりがあるのを発見。1コミットで20000ミューテーションを超えないようにコミットを分割する処理に変更しました。
- またリリース後に、とある問題で全ユーザーに対して一括でデータ修正する必要が発生。MySQLであれば1回SQL流せば終わるような内容だったが、20000ミューテーションを回避するために一定ユーザー数単位でコミットするバッチ処理を準備して対応を行った。
その他、未確認事項
ごく稀にCPU使用率が謎に上がるタイミングがある。下記図のように「低/中-システム」が30%弱まで上がっている
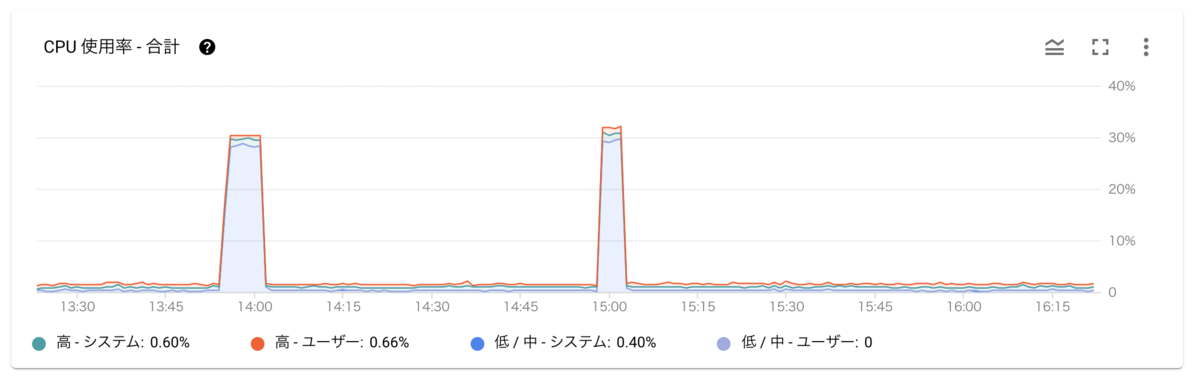
- バックアップ用のエクスポート処理以外のタイミングで発生しているので謎だが、ここの内容を見る限り、「低/中-システム」なので内部的なバックアップとかが動いている模様
データがスプリットという単位で分割されるが、その分割先や分割方法がブラックボックス
- 知らなくてもあまり大きな影響は無いが、ホットスポットが出来てないかは何か確認する手段が欲しい(下記のKey Visualizerがそれに相当する模様が詳細未確認)
Key Visualizerなる謎の機能が増えた
- ビジュアル的に問題になっている箇所とかを表示するような機能らしい
- 説明
個人的に不思議に感じたのが、整数型がINT64のみ
まとめ
注意点に関しては初めてのものに対する特有の不明点が多いという感じなのでで知っておけばそれほどの問題にはならないものかと考えています。
また、良い点(特にフルマネージドとオートシャーディング)が魅力的なので、導入予定がある場合は思い切って導入してしまうのをお勧めします。
最後に
リベル・エンタテインメントでは、このような最新技術などの取り組みに興味のある方を募集しています。
もしご興味を持たれましたら下記サイトにアクセスしてみてください。